
一、前言
【起因】:一些近期的攻击表明,在训练过程中简单地保持数据定位(data locality)并不能确保足够的隐私保证。
【需求】:需要一种联邦学习系统,它能够防止对“训练过程中进行交换的信息”和“最终训练的模型”进行推理攻击,同时还能确保推理的模型具备可接受的精确度。
【现状】:现有的联邦学习模型大多使用SMC(secure multiparty computation, 安全多方计算),这种方法在具备大量parties,并且每个parties相对拥有较少的数据量时,很容易受到推理攻击或者差分隐私的影响,导致很低的精确度。
【创新】:提出了一种把差分隐私和SMC技术联合在一起的方法,这使得在parties的数量增加的时候,可以减少噪声的添加而无需牺牲隐私,同时还能使系统保持预定义的可信度。除此以外,该方法还具备广阔的适应性,能够训练诸多的机器学习模型。
二、介绍
本部分主要是对上述“起因”和“现状”的扩充描述。包括了以下几点:
分布式训练系统,扩展了传统的机器学习步骤,它通过使用一系列的训练节点处理分享的数据,或者把数据从中心结点发送到一系列的可信参与结点。
但在涵盖了大量组织的学习场景下,训练模型不得不包含诸多的不可信群体。
这些组织由于法律的限制或者竞争的客观情况,彼此之间无法共享数据,导致模型的效率低下。
联邦学习是解决这个困境的一个反向。它旨在让数据持有者之间互相协作,而不是指定一些受信任的第三方。这些数据持有者们在本地各自运行模型,同时能且仅能交换模型的参数。
上述问题解决了训练的问题,但带来了隐私保护的困境。有的通过引入一个可信的数据集成者,有的往本地添加差分隐私,以此来解决隐私保护的问题,但这样带来了效用的问题。
三、前置知识
3.1 差分隐私
前面已经详细介绍过了,在此不再赘述。本文作者使用的是带有δ的差分隐私定义。
3.2 阈值同态加密( Threshold Homomorphic Encryption )
简单来说就是,在加性同态加密下,存在如下性质:
而阈值变体在此基础上进行了扩展。在阈值变体中,一组参与者能够共享密钥,而小于预定义阈值的各方子集都不能解密。
3.3 联邦学习中的隐私问题
在常规的情况下,一个单独的个体P,使用数据集D,在算法fM的学习下,获得了一个模型M,也就是 fM(D)=M。这个情况下,P能够获取整个数据集D。
但在联邦学习预设的环境下,存在多个用户端P1, P2 … Pn, 每个端有各自的数据集 D1, D2, …, Dn, 而整体的目标是使用所有的数据集来学习一个模型。
在这样的情况下,必须考虑两个对数据隐私可能产生的威胁:①对学习过程的推理;②对结果进行推理。
前者表示可能存在部分群体利用训练过程中的参数交换来推测其他参与者的信息。后者表示从输出结果中泄露了任意参与者的数据。
作者设想了两种类的攻击:
①内部攻击,由数据持有者或者第三方发起
②外部攻击,包括对参数交流、最终部署模型的窃听
对学习过程的推理攻击。SMC允许参与者在n个输入中获得输出,同时阻止其了解此输出以外的任何内容。但攻击者可以从输出来推测输入的可能结果。因此,必须对可能的输出进行分析。
对输出结果的推理攻击。基本依靠差分隐私机制来解决这个问题。
四、一种可信的端到端的方法
4.1 攻击模型
作者设计了一个系统,这个系统能够承受三种可能的攻击者:①来自集成者;②数据端;③第三端外端。以下分别进行相关的介绍:
“诚实但是好奇的集成者”(Honest but Curious)攻击模型:主要是SMC和数据挖掘的领域。集成者首先遵循联邦学习的规范和协议,但是会尝试根据收集到的信息对隐私数据进行推理。
“串联端”(Colluding)攻击模型:假设可信方的数量是最少的。在该模型中,不同于上一种那样的“Honest”前提,这种情况下部分端是可能会偏离协议而尝试去获取那些honest端的额外隐私数据的。
“外部(Outsiders)”攻击模型:这种模型里主要考虑的是来自系统外部的攻击。除了第三方之外,还包括对“使用最终模型的用户”的警惕性。
除了上述的攻击模型之外,作者还设定了如下的一些假设:
交流(Communication):在端到集成者之间是安全信道。
系统设置(Set up):使用Paillier阈值变体系统来确保任意小于等于n-t的端不能够解密。这个设置是为了确保个体信息的隐私能够送达集成者处。
4.2 提出方法
考虑如下场景:存在n个多方的端:P1, P2, …, Pn,一系列独立的属于各个端自己的数据集 D1, D2, …, Dn,一个集成者 A。
系统包含了三个输入参数:fM, ε 还有 t 。其中,fM表示训练算法,ε表示为了抵挡推理而需要的隐私预算,t表示最小的诚实无串通端的数量。
集成者A运行学习算法fM,这个算法包含了至多k个查询Q1, Q2, …, Qn,每个查询都是从这n个数据集里请求数据。这些信息里可能包含了学习训练后的模型参数、也有可能是一系列的传统查询操作。在算法中,每一个对隐私的、本地数据集的步骤s都应该表示为Qs。而参与者会通过基于算法fM的差分隐私机制来添加噪声。加噪后的回复通过阈值变体Paillier加密系统加密,并传输给A。
同态加密允许A来集成各个数据。A连续向至少n-t+1个端查询来解密,然后更新模型M。在fM 执行完毕的时候,模型M会暴露给所有的参与方。算法如下下所示:

对于串通推理攻击,一共有两步:(1)添加噪声;(2)在加密方案的阈值设置 中。
参与串通的人越多,那么可供推理Honest用户的信息就越多,因此,噪声应该要能够符合串通攻击的底线。而使用同态加密算法能够在精度上显著提高。
4.3 利用SMC减少噪声
令σs和Ss表示噪声参数、Qs的敏感度,εs表示隐私预算。
传统的联邦学习DP方法中,每一端都使用高斯机制来向它们对集成者的回复r i,s 中添加噪声 。
但是,如果每个回复中都使用了阈值为n-t+1的机制进行加密,那么噪声或许就可以减少t-1个因子。如:
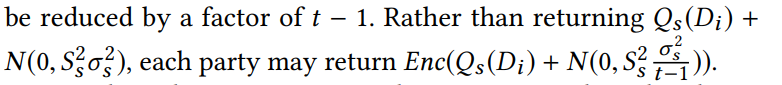
注意到当A集成了这些回复时,值最终被解密成
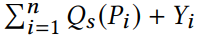
且每个Yi都是高斯分布中以标准
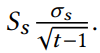
抽取而来的。这和
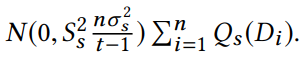
等价。注意到t-1小于n,因此解密的噪声值是严格大于需要满足的DP要求的。除此以外,加密机制确保了最大串通者数量(n-t+1)下不能够解密honest端的值。
五、实验评估
5.1 决策树
决策树中,每个被 P i 拥有的数据集 D i 会包含一系列实例,这些实例由分类特征F和类型属性C进行的描述。一开始由集成者用一个根结点来初始化决策树。然后,根据从每个P 进行的记数查询中选择最大化信息增益的特征F,并且为F的每个可能值生成一个子结点。之后该特征F将从集合中移除。这个步骤不断重复,直到:
特征池中没有更多的特征
达到预定的最大深度
响应的噪声太嘈杂而被认为无意义了
在隐私、联邦学习中有两种类型的参与者查询:统计和类统计。集成者A首先把整个隐私预算ε根据树的每一层而均分。根据差分隐私的构成特性,由于同一层内的不同结点在数据集不相交的子集上进行评估,它们不会累积隐私损失,因此分配给每一层的预算不会进一步划分。对于每一个结点,一半的隐私预算被分配来决定总的记数,一半被分配于其他类统计或者评估属性。对于内部结点,评估每个特征以针对同一数据集来进行划分。因此,分配给评估属性的预算必须进行划分。最大深度为 d = |F|/2。
比较方法:比较两种随机基线和两种现在的 FL 方法。随机基线使我们能够表征特定方法何时不再学习有意义的信息,而 FL 方法能够可视化相对性能成本。
Uniform Guess:类预测随机抽样,给每个类赋予一个1/|c|的机率。
随机高斯:从上者演变而来,考虑了训练集里的类值分布。
本地DP:各方添加噪声以单独保护自己的数据隐私。
无隐私:无隐私保证情况下的测试。
以下是通过控制变量法,通过对隐私预算、端的数量和信任参数三者的控制变量来进行比较。
- 隐私预算:
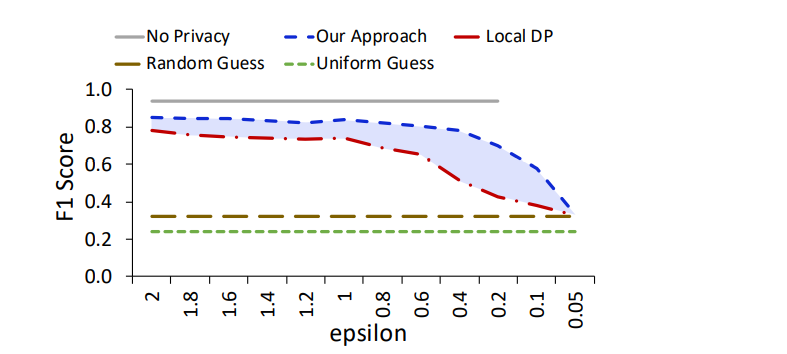
- 首先关注隐私预算对系统性能的影响。为了隔离隐私预算的影响,把端的数量设置为10,假设不存在串通。假设预算值在0.05到2.0之间。由于差分隐私机制的特性,隐私预算ε和添加的噪声量成反比。换而言之,ε越小,隐私预算越小,添加的噪声越多。
- 在ε为0.4的时候,F1分数(精确率和召回率的调和平均数)为0.8。当ε小于0.4的时候,噪声就会盖过所提供的信息,导致精度下降。图中可见,作者的方法比本地DP有着更好的性能。:
- 端的数量:
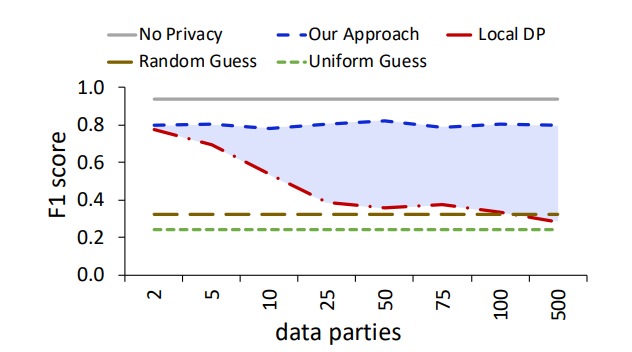
- 联邦学习除了需要考虑上述的ε预算来调和隐私和效用之外,还需要考虑的一个重要点是“在高度分布式场景中保持准确性的能力”。像一些物联网的场景里,多方各自都有一些数据时,这时端的数量也会对性能造成一些影响。
- 固定好ε为0.5,假设不存在串通,结果如下所示。这个结果暴露了本地DP方法的弱点,当端数增加时,Local DP方法的性能会急剧下降。
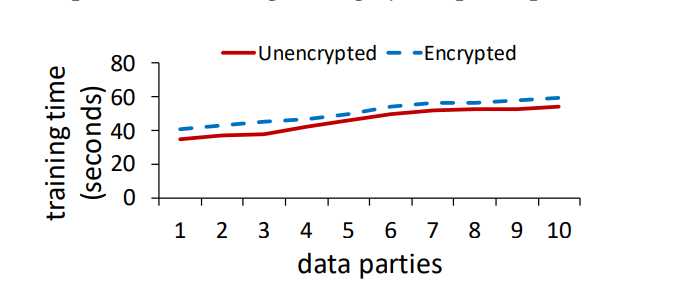
- 除此以外,密钥系统的开销也和参与者的规模相关。如图所示,加密的系统减去非加密的系统,得到的就是加密的开销。可以看到,在端数量从1增加到10的过程中,尽管系统成本开销在不断增加,但是加密过程却能够始终保持一致。这是因为该系统是为了分布式场景设计的,与集成者的交互是并行完成的。
- 受信方:
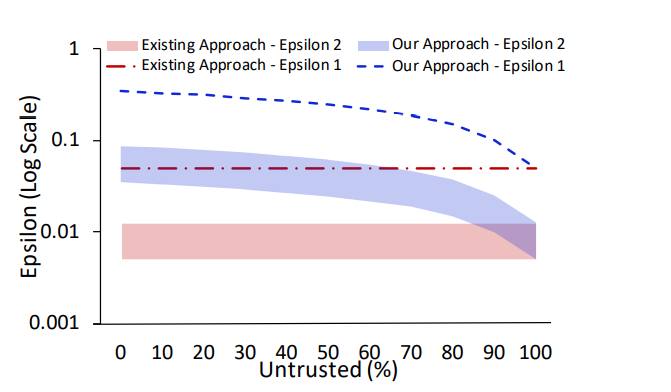
- 信任参数代表了系统能够容忍的、拥有最大串联者数量下的对抗知识的程度。
- 最坏的情况,除了自己之外,其余人都是串通的,这种情况下,仍旧能够收敛。其他情况下,随着ε的增加,作者的方法都能产生更高的精度。
5.2 卷积神经网络
与集中训练的CNN类似,每一端都被发送了一个具有相同初始结构和随机初始化参数的模型,然后,每一端将在本地完成一个epoch的学习。在每一batch结束时,根据裁剪值C和隐私参数δ引入高斯噪声。一旦整个epoch或者1/b个bathch完成,最终参数将会发送给A,然后A对参数取均值,并将更新的模型发送回来来进行下一个epoch的学习。在经历完了预先设置好的E轮周期学习后,输出最终的模型。
如果 ,那么该方法里每个随机采样的batch都将符合(ε,δ)-差分隐私。使用矩统计,那么整体上将呈现
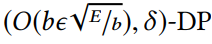
数据和模型结构:使用了MNIST数据集。模型结构为:一个前馈神经网络,具有2个内部ReLU单元层和一个具有交叉熵损失的10个类的softmax层。第一层具备60个单元,第二层包含1000个。将裁剪尺度C规定为4,学习率设置为0.1,批处理率b设置为0.01,使用带有Tensorflow后端的Keras。
比较模型:
- 中心数据持有者,无隐私:数据由一端中心持有,无隐私保护。
- 中心数据持有者,保护隐私:数据由一段中心持有,具备隐私保护。
- 分布式,无隐私:数据分布在各个端里,无隐私保护。
- 本地DP:分布式数据端,用户往自己的数据里添加噪声。
这是比较的结果:
在端数为10,包含了100个训练周期,隐私参数σ设置为8,该方案的F1分数接近0.9,由于local DP方法。如果把隐私参数σ设置为4,那么带隐私的中心数据持有者方法,F1为0.96,本地方法为0.864,该方案为0.957。当σ设置为2时,这些数据为0.973,0.937,0.963。由此发现,随着σ的增大,该方法的相对收益也会更大。
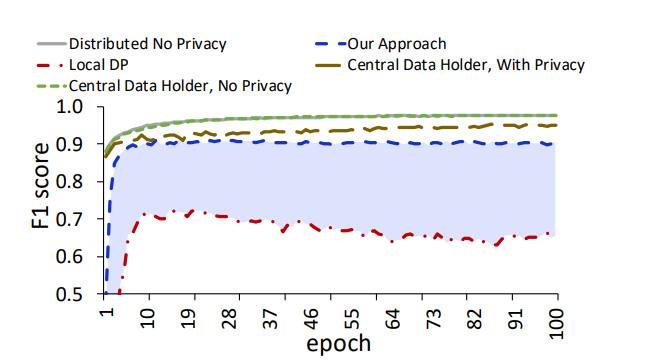
- 可信方:如图所示,这里展示了该方案在随着可信方逐渐下降时,噪声标准差的增加情况,以及相对LOCAL DP的优势。能够产生这样的优势,主要是由于加密解密过程完全可以并行进行。
5.3 支持向量机
为了以隐私分布式方式训练线性 SVM,集成者将具有相同权重向量 w 的模型分发给所有各方。然后每一方运行预定义数量的 epoch 以在本地学习。为了在此设置中应用差分隐私,我们首先对特征向量 x 执行规范裁剪以获得梯度更新灵敏度的界限。然后,将高斯噪声添加到梯度中。在每一方完成其本地训练后,最终的噪声加密权重被发送回集成者。集成者对加密的权重进行平均,并发送回带有新权重向量的更新模型,以用于下一个学习阶段。训练在预定义数量的 epoch 后结束。
数据集:Gisette数据集
比较模型:
- 中心,无隐私
- 中心DP
- 分布式无隐私
- 本地DP
学习率设置为0.01,进行100次epoch,除此以外,对于联邦学习,每个端跑10次epoch,使用10个不串通的端,隐私参数设置为σ=4,差分隐私为(5,0.0059)。结果如下所示:
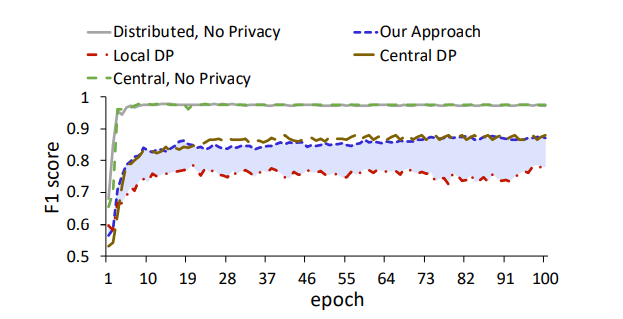
在设计隐私保护的模型中,该方案的F1分数为0.87,和中心DP差不多。
在低可信度的设置里,该方案的F1分数为0.85,Local DP只有0.75。
这些实验结果表明,该方案始终优于以Local DP方案和基线方案,同时也接近那些不进行隐私处理的方案。
六、系统实现
6.1 隐私决策树训练的实现
决策树的构建一般包含了三个步骤:
确定能够最大划分决策树的特征
根据选择的特征来划分训练数据
重复上述两个步骤,直到达到停止条件为止。
作者的构建如下:
确定划分数据的“最好”特征。对于“最好”的定义,作者的理解和构建ID3决策树一样,是使用“最大化信息收益”的特征。对于信息收益,使用的参考量是信息熵,这部分可以参考“机器学习”包中笔者有关“决策树”的相关文章来理解。
给定向各方查询类计数的能力,集成者可以控制迭代学习过程。为了确保这个过程根据预定义的隐私预算是符合差分隐私的,作者按照[19]中的方法来划分每次迭代的预算,并设置固定数量的迭代而不是纯度测试作为停止条件。如果计数相对于噪声程度太小而无法提供有用的信息,算法也会停止。
整体的算法如下所示:

6.2 隐私神经网络训练的实现
- 部署隐私神经网络系统的步骤和决策树不同。根据预定义的结构初始化模型之后,接下来的步骤为:
- 把数据集洗牌,然后平均归入batches中;
- 每个batch都迭代地通过模型;
- 损失函数在每个batch中计算错误;
- 错误前向传播到网络,然后通过随机梯度下降算法在处理下个batch之前更新网络的权重;
- 不断重复上述步骤,直到模型收敛为止。
作者倾向于把每次向数据端的查询作为一次Local学习的周期。也即:每个端完成上面的四个步骤,以此作为一次迭代,然后把更新的模型传输给集成者。集成者对提供的每个权重取均值,再把更新的模型和一个新的查询传送回来,以此作为一个新的周期的开始。
每一个周期会收集噪声参数σ,整体隐私预算的成本将通过一个独立的隐私矩效用来决定的。当周期数到达预先指定的数字时,该算法将会停止,如3所示:

对于端的训练,每个batch都是以相同的采样概率b来随机采样的。这样,“一个周期”的定义就变成了要处理|Di|样例的批迭代次数。
此外,还对更新损失函数的参数进行了裁切,来保证神经网络的敏感度。在权值更新的时候,再加入噪声。一旦一个整体的周期完成了,模型将会传输给集成者。

6.3 隐私支持向量机训练的实现
- 最后是对于经典的 具备铰链损失的l2正则化二元线性SVM问题。其损失函数如下所示:
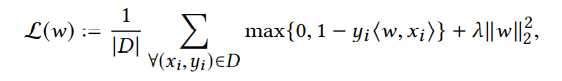
- 对于集成者来说,SVM的训练过程有点类似于神经网络训练。对数据方的每个查询都定义为 K 个训练时期。一旦收到查询响应,模型参数就会被平均以生成一个新的支持向量机模型。然后将这个新模型发送给数据方进行另一个 K epochs 的训练。我们再次指定一个预定数量的 epochs E 来控制训练迭代的数量。基本上和隐私神经网络处的训练过程一样。

- 为了在每个数据端完成一个周期的训练,我们在本地的训练数据集Di上进行迭代。同样,在这里进行了梯度的裁切工作,来保持对于参数更新的敏感度要求。之后模型参数、噪声参数会根据损失函数来更新。算法 6 概述了每个数据方为响应集成者查询而进行的 K 个训练时期的过程。

6.4 算法库的扩展
由于选择了将阈值 Paillier 密码系统与集成器结合使用,而不是由各方自己运行的复杂 SMC 协议,我们可以在集成者和各方之间提供流线型的接口。各方只需要用加密的、嘈杂的响应来回答数据查询,并用部分解密值来回答解密查询。全局模型的管理和与所有其他方的沟通由集成者负责,因此降低了各方参与联邦学习系统的门槛。这种方法能够有效地处理将更多方引入联邦学习系统,而不会增加加密开销。
部署新机器学习训练算法的另一个问题是算法参数的选择。使用该系统时必须做出关键决定,其中许多是特定领域的。作者的目标是通过他们在第 5.1.1 节中对隐私、信任和准确性之间的权衡分析来为此类决策提供信息,但请注意,影响会因数据和选择的训练算法而异。虽然该系统将减少训练任何联合 ML 算法所需的噪声量,但围绕各种特定数据特征对隐私预算的影响的问题是特定于算法的。例如,算法 2 演示了在决策树训练中,特征和类别的数量如何影响每个级别的隐私预算。类似地,算法 4 和 6 显示了范数裁剪在神经网络和 SVM 学习中的作用。在神经网络中,这个值不仅会影响噪声,还会对学习产生不同的影响,具体取决于网络的大小和特征的数量。
七、整理
其实我不是很喜欢这种先把成绩放在前面,对于主要的实现却很简略地叙述的论文结构,因为这需要额外花很多时间来研究作者的工作(〃>目<)
概述一下,本文的主要工作是提出了如何在联邦学习的背景下,进行符合差分隐私规范、而又不特别损失效用的方法。主要的思想就是在数据端和集成者中间使用同态加密进行数据的传输。每次进行训练时,端处先进行一个周期的训练,然后将数据发送给集成者。集成者对结果取均值后,带着下一次的查询分别访问各个端,这样不断重复训练周期,直到达到预定的训练目标为止(预定的树深、预定的周期数等)。在训练的时候,为了符合敏感度的规范,分别对模型和噪声的参数进行裁切。作者还将这个步骤扩散到了决策树、神经网络、支持向量机里。
该论文的方向包含了三个:联邦学习+同态加密+差分隐私下的深度学习,也因此本文也涉及到了诸如可信度、共谋串通等问题。但对于这些部分,作者并没有详细讲述同态加密是如何避免串通共谋情况的发生的,而只是将其作为一个衡量性能的参数。因此,本文虽然看起来像是“3-4”、“3-5”那样的“差分隐私应用化”,但实际上却更加偏向于“差分隐私下的学习方法的改进”这个论题。这就导致同态加密的部分,也即如何进行加密、解密,同时防止串通的部分,相当简陋和模糊,这也是笔者认为本文的不足之处。
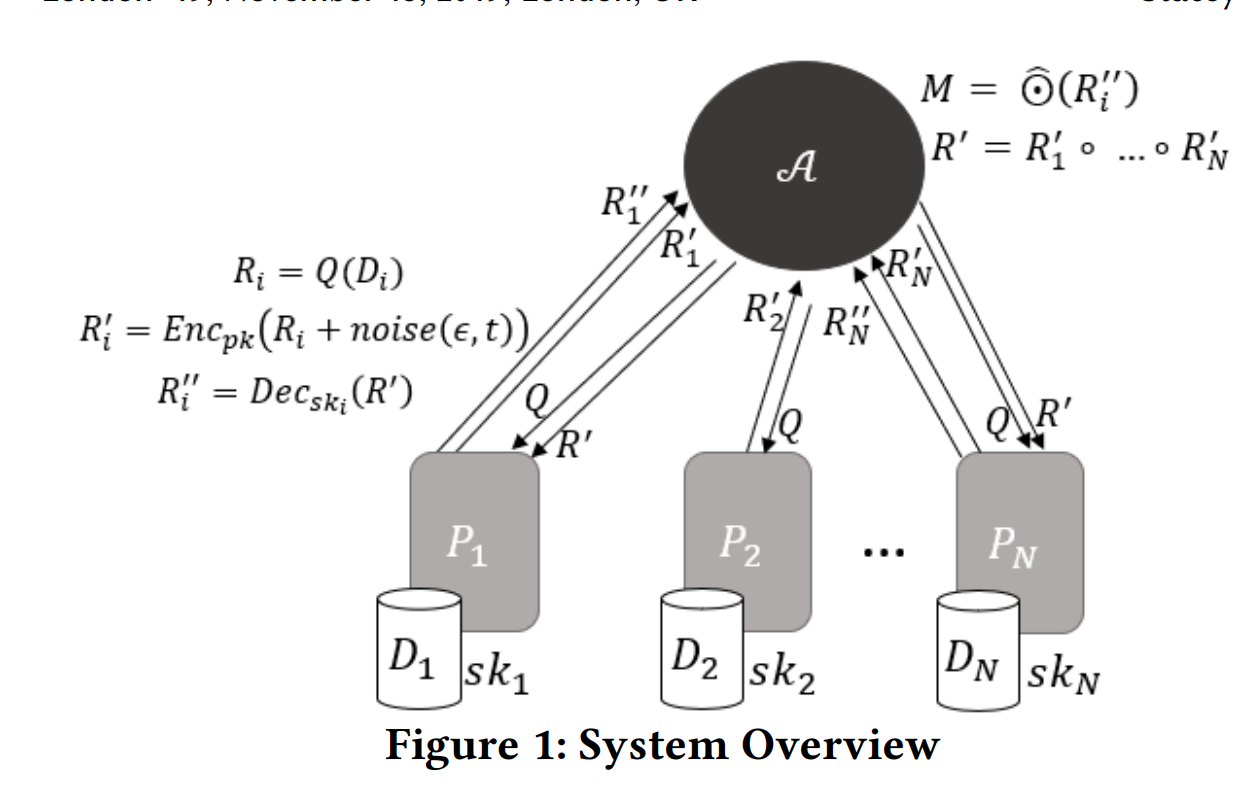
比如同态加密的步骤。作者给出了图1:
其算法为:

这个算法做了三件事:
首先由集成者A向各个数据端进行查询,数据端往查询结果里添加噪声,然后通过同态加密传输给集成者。
集成者在同态加密规则下进行数据集成。然后选择至少n-t+1个数据端,用加密后的结果去访问这n-t+1个数据端,并获取rs的部分解密。
集成者根据部分解密来计算rs,并更新模型。
这个算法的关键应该在于上述的第二步,也是比较困惑的点。集成者收集到了N个加密的数据,并集成处理了。根据抽屉原理,抽选到的n-t+1个人里至少有一个可信者。接下来,部分解密、以及如何计算rs的部分,就比较难理解了。只包含了n-t+1个人,集成者又是怎么解密所有信息的呢?
其余部分主要是对主流的机器学习算法进行了差分隐私和联邦学习化。因为遵循了异步规范,所以即使端数增加,整体的成本也不会增加多少。除此以外,在诸如神经网络等训练步骤,其实就是把原本中心dp的思路切割为了一个个小的步骤,仍旧是在梯度更新的时候添加噪声,然后做了一个同态加密与解密,以此实现联邦学习。这比直接往数据集添加噪声然后传输来达到隐私保护目的的local DP精度要好不少。这也是本文的优势。